


📣 Issues will now have podcasts attached, so I’m re-releasing this post with the added podcast.
If you’re new, subscribe for free! 👇 And read the intro post here.
You can have an edge in the way you approach the markets, a method you use, a setup you trade, or even a mindset. Whatever floats your boat, as long as it’s measurable. It also doesn’t have to be unique to you, it can be a common setup and maybe you just exploit it better or differently than the next trader.
The only certain thing is that if you’re trading without an edge, you’re the sucker at the poker table. Trading without knowing your edge is arguably just as bad.
It’s worthwhile investing some time and effort into refining your trading by collecting and exploring your own data.

It can also be a powerful way to build conviction early in your trading journey. Okay, dead horse beat. Let’s explore methods for collecting data.


The example above is a regression analysis I ran on a specific setup of mine—intended to be traded in a specific way, with specific parameters, under specific market conditions. Dots on the chart that stray too far from the trend-line are setups that are outliers, performing out of the norm.
This type of analysis is a great way to introduce rigor to the process of trade selection. The outcomes from taking those setups, win or lose, are then by nature more easily measured; improving your data collection overall. Sounds great! But it’s no small task like anything worthwhile in trading.
At the end of the day, we’re looking for a pattern in your trading or setups that we can reproduce to fine-tune your performance and better define your edge.
a. Define your setup
For the example below, we’ll use a simple bull flag breakout. I would boil down the 1-3 setups that you’re willing to spend a significant amount of time studying and pick one to start.
You need a defined setup to continue.
b. Make the setup reproducible
Your goal now is to convert everything that may be relevant to the outcome of your setup into a data point. Begin by assigning letters to each of the key points in your pattern. 🥳 You now have reference points for your spreadsheet.

X-A references a the start of your pattern, and F-G references the breakout. Now you can begin collecting data on the setups you trade across different stocks and referencing them in your spreadsheet.
Here’s an example from one of my sheets on what this data may look like.
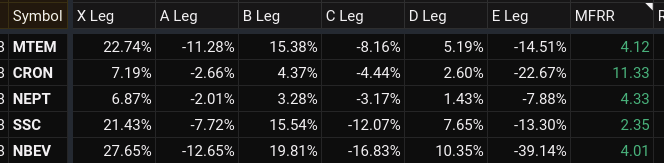
You can see that I was able to calculate the MFRR, Maximum Favorable Risk to Reward, from this data set. Just one of the many data explorations you can do that can help inform your trading decisions.
Be sure to include external factors as well, like fundamental parameters, or anything that weighs on how you would take the setup during live trading. You want to model the data to be as wide as possible, then work towards narrowing it down.
c. Trade the setup 1,000 times
To extract statistically significant insights from your data, you need a large data set.
It’s only after 1,000 trades, traded in the same way, under the same conditions, that you are able to confidently assign a statistical probability.
Don’t worry, there are shortcuts. You can backtest setups manually—or with an algorithm— and walk trades forward to glean more data from your backtest results. This can be as simple or complicated as you want. Just stick to the goal of collecting good consistent data.
In the past I’ve used the ThinkorSwim on-demand feature, I’ve also manually walked the chart back on TradingView which works really well, and I’ve even gone as far as writing a python script to scrape what I need from stock data feeds.

d. Statistical exploration
Exploring data is a very large topic. I’ll cover a couple of examples to get you started but this area is where you’ll need to do some leg work and find the best analysis that fits your specific setups.
**Please note that I am not a data analyst, I’m simply sharing what works for me. Happy to take suggestions in the comments.
Linear Regression
Is there a correlation? The linear regression example I showed above is one method that, once you wrap your head around, is very easy to apply to any data with multiple variables to predict the relationship between different factors and output on a graph.

For example, plotting returns vs position sizing and running a regression may give you a high correlation which can give you insight into how position sizing affects your returns. The points on the chart would closely follow a linear regression, the tighter they follow the higher the correlation.
Using this method you can identify outliers to refine your setup or performance.

Here are some resources to get you started:
Standard Deviation and Mean
How do you know how far your data is straying from the mean? Standard deviations! 🤓
The standard deviation is the average amount of variability in your dataset. It tells you, on average, how far each value lies from the mean. A high standard deviation means that values are generally far from the mean, while a low standard deviation indicates that values are clustered close to the mean.
Let’s look at an example using trade data. The charts below show that returns are much more concentrated to the mean in the short term. As we go out to the monthly view, the mean shifts dramatically and we get a more sporadic return distribution.

As a trader, the insight would be to focus on the outliers and work on tightening up the longer-term return distribution.
Here are some helpful resources:
Introduction to Statistics Using Google Sheets(this is a monstrous, but an extremely helpful document that everyone should save to disk.)
In closing
Don’t be overwhelmed by the complexity of this issue. It’s completely expected to be lost when it comes to this subject, trading is hard enough without having to do all of this spreadsheet statistical work. Think of it as something you’ll get better at as you learn.
The next time you trade, consider keeping a detailed log to make it easier on yourself in the future. You’ll regret not collecting data as early as possible.
💬 Happy to explore further in the comments! Also, if this is an interesting topic for everyone, I can try to get a statistician or data analyst on the next podcast episode to set us straight.
— Del (twitter)






